








Enterprise grade GPU servers

HP enterprise servers
Your GPU configuration is installed on Hewlett Packard Enterprise servers, stress tested for 100% compatibility and stability.

Choose your data center
Get a GPU dedicated server, deployed in one of our New York, Miami, San Francisco, Amsterdam or Bucharest data centers.

Low latency network
Your server is connected to a custom-built, low latency global network.

Support
Get access to instant support, from real humans, available around the clock via phone or live chat.
Unbeatable prices
Found it somewhere else cheaper? Take 10% off the lowest advertised price. Contact us for details.
5 minutes deployment
Access your bare-metal GPU server within 5 minutes, once your payment is verified.
24/7 Support
Instant, round-the-clock support provided by a team of GPU server experts.
See ConfigurationsHourly price per A100 GPU
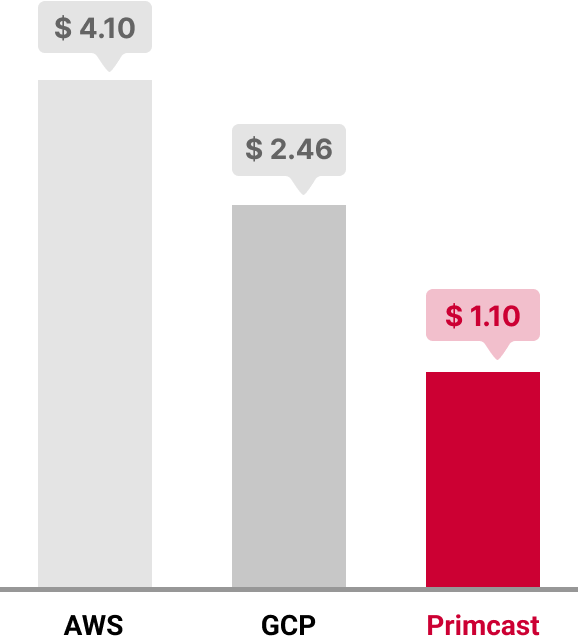
*Pricing based on a single A100 GPU with 40GB VRAM.

NVIDIA’s latest generation of GPUs pushes the boundaries of gaming and creative performance with cutting-edge advancements in graphics rendering and AI acceleration. Built on next-gen architecture, these GPUs offer improved power efficiency, significantly faster ray tracing, and remarkable computational capabilities. With higher CUDA core counts and faster memory bandwidth, the RTX 50 series delivers ultra-realistic visuals, smoother gameplay, and superior performance across demanding workloads.
GeForce RTX 5080 Specifications
GeForce RTX 5090 Specifications

Unlock the pinnacle of gaming and creative performance with the NVIDIA GeForce RTX 4090D. Powered by the groundbreaking Ada Lovelace architecture, this GPU delivers remarkable power and efficiency for ultra-realistic graphics and immersive experiences. With enhanced ray tracing and AI-driven features, the RTX 4090D offers real-time, cinematic-quality rendering, incredibly fast frame rates, and exceptional performance across the most demanding applications and games.
RTX 4090D Specifications
Compatible with Linux, CUDA/OpenCL, DirectX, Windows.
Order configuration
Nvidia's new generation of Ampere-based GPUs brings significant improvements over the Turing Quadro RTX series. With double the processing speed for single precision floating point (FP32) operations and greater power efficiency, the RTX A generation delivers more visually accurate renders and 2x faster ray-tracing. The enhanced version of NVIDIA NVLink accelerates graphics and computing workloads.
QUADRO RTX A4000 Specifications
QUADRO RTX A5000 Specifications
QUADRO RTX A6000 Specifications

NVIDIA’S GeForce RTX 30 Series graphics cards run on Ampere architecture, 2nd generation RTX, featuring several new technologies, from faster Ray Tracing and Tensor Cores to advanced streaming multiprocessors. The GeForce RTX 30 Series GPUs are defined by their innovative thermal design that delivers almost 2x the cooling performance of the previous generation. The world’s fastest graphics memory, GDDR6X, delivers remarkable performance that makes it perfect for resource-intensive applications such as AI, visualization, and gaming.
RTX 3070 Specifications
RTX 3080 Specifications
RTX 3090 Specifications
Compatible with Linux, CUDA/OpenCL, KVM, Windows.
Order configuration
The NVIDIA Quadro RTX series gives you access to the well-known Turing™ chip architecture that reformed the work of millions of designers and creators. Hardware-accelerated ray tracing, state-of-the-art shading, new AI-based abilities, all for enabling artists to increase their rendering capabilities. The Turing Streaming Multiprocessor architecture features 4608 CUDA® cores, and together with the Samsung 24 GB GDDR6 memory, supports complex designs, 8K video content, and enormous architectural datasets.
QUADRO RTX 5000 Specifications
QUADRO RTX 6000 Specifications
QUADRO RTX 8000 Specifications
Compatible with Linux, CUDA/OpenCL, KVM, Windows.
Order configuration
Get access to the best performance and features from a single PCI-e slot with NVIDIA’S QUADRO RTX 4000. State-of-the-art display and memory technologies combined with the Turing™ chip architecture delivers photorealistic single ray-traced rendering in a fraction of a second. This GPU features RT Cores, optimized for ray tracing, and Tensor Cores, perfect for deep learning projects. Now you can create authentic VR experiences and enjoy faster performance when it comes to your AI applications with a cost-effective solution.
QUADRO RTX 4000 Specifications
Compatible with Linux, CUDA/OpenCL, KVM, Windows.
Order configurationVideo
Transcode up to two video streams simultaneously, through the new Turing chip architecture.
3D Rendering
Use the power of the RTX 2080 to render 3D graphics faster than ever.
Mining
Mine cryptocurrency through the new Turing chip architecture, found on the RTX 2080 and RTX 2080 Ti.

NVIDIA’s Ampere Architecture, the successor to Volta, and is the fundamental solution for AI acceleration, from the edge to the cloud. The NVIDIA A40 chip enables multi-workload capabilities with ultra-modern features for ray-traced rendering, VR, and more. Second generation RT cores deliver 2X the throughput over the previous one, the third generation Tensor cores provide 5X more training capabilities, and the 48 GB GDDR6 memory is more than enough for engineers, data scientists, and their large datasets and workloads. The NVIDIA A100 Tensor Core GPU is a revolutionary leap for AI, as it delivers unrivaled acceleration at every scale, with NVIDIA’s Multi-Instance GPU (MIG) technology that allows the efficient scaling of thousands of GPUs. The third generation Tensor cores provide up to 20X more performance, and the MIG technology lets multiple networks operate at the same time on a single A100 GPU, optimizing computing resources.
NVIDIA A100 Specifications
NVIDIA A40 Specifications

The T4 introduces Tensor Core technology with multi-precision computing, making it up to 40 times faster than a CPU and up to 3.5 times faster than its Pascal predecessor, the Tesla P4. Get access to 8.1 TFLOPS of single precision performance from a single T4 GPU. Transcode up to 38 full HD video streams simultaneously with a single Tesla T4 GPU paired with our HPE BL460c blade server. *Results may vary, based on server configuration.
Specifications
Compatible: VMWare ESXi, Citrix Xenserver, KVM, Linux, Windows.
Order configuration
The Coral USB Accelerator
You can now add an Edge TPU coprocessor to any Linux-based system with the Coral USB Accelerator designed by Google. The small ASIC chip provides high-performance ML inferencing with low power cost. For example, it can execute 100fps on MobileNet v2 models, while using very little power (500mA at 5V).
Specifications
Compatible with Linux machines, Debian 6.0 or higher, or any derivative (such as Ubuntu 10.0+), but also with Raspberry Pi (213 Mode B/B+).

NVIDIA’s new Turing chip architecture delivers up to six times the performance of previous generation GPU’s, with breakthrough technologies and next generation, ultra-fast GDDR6 memory.
RTX 2080 Specifications
RTX 2080 TI Specifications
Compatible with Linux, CUDA/OpenCL, KVM.
Order configurationMining
Use the 2560 cores to mine your favorite cryptocurrency.
3D Rendering
Faster 3D graphics processing, allow you to increase productivity and revenue.
Compute
Run your CUDA and OpenCL applications at optimal performance by using the computing power of the GTX 1080.

NVIDIA’s previous chip architecture, great for mining, graphics rendering and computing. The NVIDIA Pascal architecture delivers excellent performance at a budget friendly price.
Specifications
Compatible with Linux, CUDA/OpenCL, KVM.
Order configuration
An optimal chip for machine learning and video transcoding, can be found in the NVIDIA Tesla P4 and P100 GPU’s. NVIDIA’s Pascal chip architecture has been proven to be faster and more power efficient than its Maxwell predecessor. Transcode up to 20 simultaneous video streams with a single Tesla P4 paired with our HPE BL460c blade server. * A more powerful version of the Tesla P4 is the Tesla P40, with more than twice the processing power of the Tesla P4. The Tesla P100 GPU, is most suitable for deep learning and remote graphics. With 18.7 TeraFLOPS of inference performance, a single Tesla P100 can replace over 25 CPU servers. *Results may vary, based on server configuration and video resolution of each stream.
Specifications
Compatible: VMWare ESXi, Citrix Xenserver, KVM, Linux, Windows.
Order configuration
The first GPU to break the 100 teraflop barrier of deep learning performance. NVIDIA’s Volta chip, is up to 3x faster than it’s Pascal chip predecessor. Your deep learning project design can now be a reality, with little investment. Get the maximum per machine deep learning performance, replacing up to 30 single CPU servers with just one Titan V configuration. Use the Titan V for high performance computing, from predicting the weather to discovering or finding new energy sources. Get your results up to 1.5x faster than NVIDIA’s Pascal predecessor.
Specifications
Compatible: VMWare ESXi, Citrix Xenserver, KVM, Linux, Windows.
Order configurationWhy Primcast?
Add a GPU to HP enterprise hardware, designed specifically for use with GPU add-ons, eliminating incompatibility issues or poor/under performance of hardware. Your services are deployed on our global low latency network, backed by a 99.9% uptime SLA and supported by GPU server experts, around the clock.